Crawling menjadi bagian penting dalam cara kerja mesin pencari. Namun, tahukah Anda bagaimana cara Google mengcrawl artikel yang ada di internet?
Ini pengetahuan penting bagi Anda ingin mempelajari apa itu SEO lebih mendalam. Supaya punya gambaran, kami akan jelaskan konsepnya.
Pada artikel kali ini Anda akan mempelajari:
- Apa yang dimaksud crawling?
- Cara Google mengcrawl artikel.
- Proses pengindeksan halaman web.
Sebelum konten Anda terindeks oleh mesin pencari, terlebih dahulu terjadi proses crawling. Apa artinya?
Pengertian Crawling Google
Crawling adalah proses perayapan halaman web publik di internet oleh bot mesin pencari dengan tujuan untuk pengindeksan.
Google menggunakan bot bernama Googlebot. Tugasnya menelusuri setiap halaman web, menemukan konten baru, lalu menyampaikannya ke database.

Pertanyaannya, apakah setelah proses crawling ini halaman web akan langsung terindeks?
Belum.
Masih ada proses kedua yaitu rendering, baru kemudian masuk ke pengindeksan. Berikut penjelasan lengkapnya.
Cara Google Mengcrawl Artikel
Semua mesin pencari, termasuk Google, sebenarnya tidak memiliki pusat data URL di internet. Jadi, mereka tidak mendapat notifikasi jika terjadi pembaruan.
Dengan kata lain, Googlebot harus merayapi dan menemukan pembaruan itu tanpa henti setiap saat.
Jika mendapat data baru, bot akan menambahkannya ke database atau memperbarui yang sudah ada.
Proses ini bisa lebih cepat jika Anda mengunggah sitemap atau peta situs ke Google Search Console.

Secara detail, prosesnya seperti ini:
Googlebot memulai dengan beberapa halaman, lalu menelusuri seluruh tautan yang terhubung dengan halaman tersebut. Kemudian semua hasilnya dikumpulkan dalam sebuah penyimpanan berkapasitas besar.
Proses Rendering
Bot sudah merayapi halaman web, apa langkah selanjutnya?
Rendering.
Intinya, proses ini memvisualisasikan konten atau halaman seperti saat Anda membukanya di browser. Berarti juga memuat elemen CSS, HTML, JavaScript, dll.
Sejak 2019, Google menggunakan Chromium terbaru untuk rendering.
Saat melakukan proses kedua, crawler terbagi lagi menjadi dua yaitu bot untuk tampilan desktop dan seluler.
Penting! Setiap halaman web akan dirayapi oleh jenis crawler untuk desktop dan seluler. Maka dari itu, optimasi semua versi tampilan web Anda.
Setelah itu, Googlebot akan menyimpan seluruh informasi dan mencatat sinyal-sinyal penting, mulai keyword, atribut tautan, kecepatan, dll.
Proses Pengindeksan
Terakhir, data dari proses sebelumnya akan masuk ke database Google Search Index. Sekarang barulah website Anda bisa muncul di hasil penelusuran.
Tahukah Anda? Google Search Index berkapasitas lebih dari 100 juta GB dan berisi miliaran halaman.
Bagaimana cara mengetahui suatu halaman sudah terindeks atau belum?
Gampang.
Tulis tanpa tanda petik di kotak penelusuran:
“site:webanda.com” atau “site:webanda.com/url-slug”.
Jika hasilnya muncul, berarti halaman sudah terindeks.
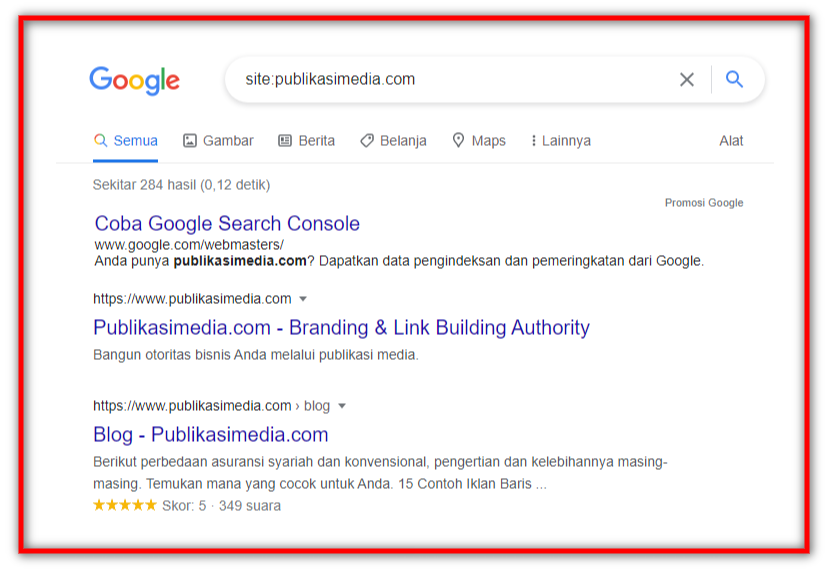
Selanjutnya biarkan algoritma PageRank yang menentukan apakah halaman tersebut layak berada di peringkat atas pencarian atau tidak.
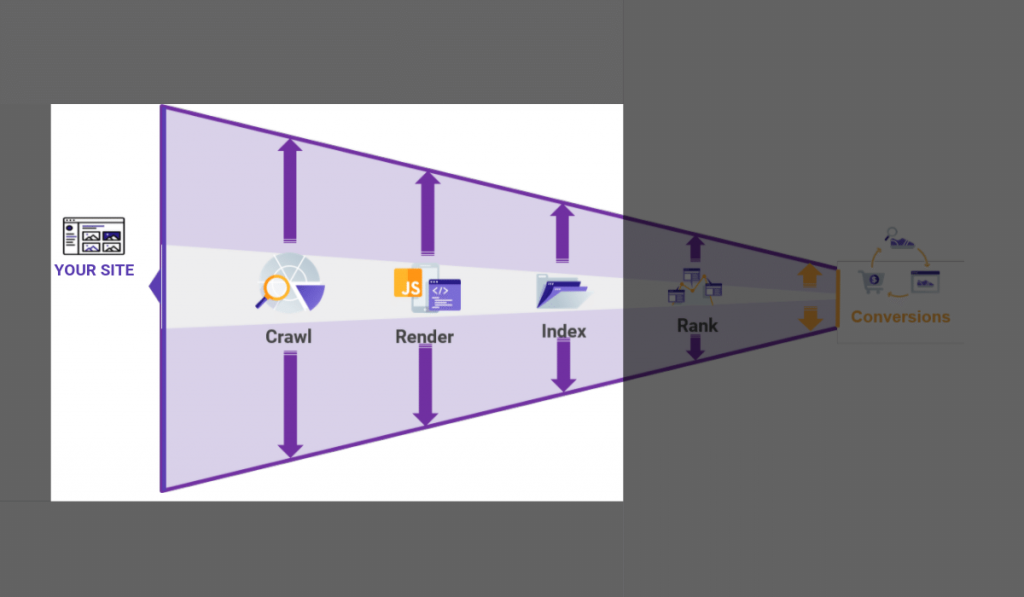
Gambar di bawah ini menunjukkan crawling hanyalah proses awal sebelum mengerucut pada ranking dan konversi.
Halaman yang Dikecualikan dari Crawling
Mengulangi penjelasan sebelumnya, Googlebot hanya merayapi halaman publik. Artinya, ada halaman yang memang dikecualikan dari proses crawling.
Ini bisa Anda lakukan dengan mengubah instruksi crawling di file “robots.txt”. Cara lainnya yaitu dengan menambahkan password pada halaman tertentu.
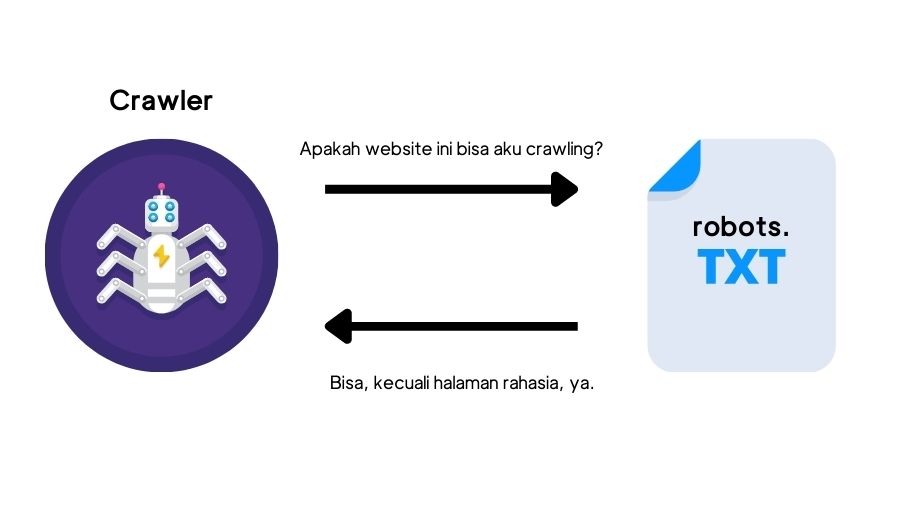
Mengapa ada orang yang menyembunyikan halaman dari crawling?
Mungkin saja si pemilik website tidak ingin webnya muncul di hasil pencarian. Misalnya karena hanya untuk uji coba atau halaman hasil pencarian internal.
Pentingnya Memahami Cara Google Mengcrawl Artikel
Banyak orang menyepelekan cara Google mengcrawl artikel. Padahal jika paham konsepnya, Anda jadi tahu betapa pentingnya sitemap hingga hal-hal SEO teknis.
Pastikan mesin pencari tidak kesulitan untuk merayapi dan mengindeks website. Jangan lupa juga jalankan strategi SEO untuk membuat artikel Anda berada di hasil teratas pencarian.
